

A little while ago ORDS version 20.2.1.227.0350 became available for download from oracle.com and was also rolled out to Autonomous Database Shared regions around the world. Oracle REST Data Services has been available on Oracle Cloud for quite some time but this is the first time the release notes specifically mention Autonomous Database Shared.
If you are running a customer-managed ORDS for your Autonomous Transaction Processing, Autonomous Data Warehouse, or Autonomous JSON Database, you must upgrade your ORDS to version 20.2.1. Failure to do so could lead to service disruptions.
Oracle REST Data Services 20.2.1.r2270350 Release Note
Why does this matter? Before answering that, some basic concepts to cover first. At a high level, an ORDS installation consists of three parts:
– The Java application that accepts, validates and processes the HTTP requests. This is the ords.war running standalone, in WebLogic Server or Tomcat Server.
– The file system that contains the configuration settings for the ords.war to make and manage database connections, as well as static files and so on.
– The database that ORDS connects to and where users define & run their REST services in. This information and the database procedures for running these services are in the ORDS_METADATA schema.
When a customer first installs and configures ORDS the database(s) which ORDS will provide a RESTful interface for, will also have ORDS specific database objects installed. The version of the ords.war and the version of the ORDS_METADATA should be the same because they are coded, built and tested together before release. While it is possible that ORDS will work just fine if the ords.war and ORDS_METADATA versions are out of synch the expected behaviour is unspecified in this scenario.

At a high level, an ORDS installation consists of the application, file system and database.
ORDS Java application ( ords.war ) version
There are a number of ways to get the application version. From the command line…
java -jar ords.war version
Update for ORDS 22+
When using ORDS 22+ the above command will show you the version but will also show this error message:
java -jar ords.war version Warning: Support for executing: java -jar ords.war has been deprecated. Please add ords to your PATH and use the ords command instead. ... ORDS: Release 22.4 Production ...
The output does give you the high level version number but the correct command to use with ORDS 22+ is in fact:
ords --version
That’s assuming the ords script is in your path. If not, the correct command is:
$ORDS_INSTALL_DIR/bin/ords --version
Now, back to the other steps to get the ORDS Java Application version number…
From the SQL Developer Web through Preferences > About…

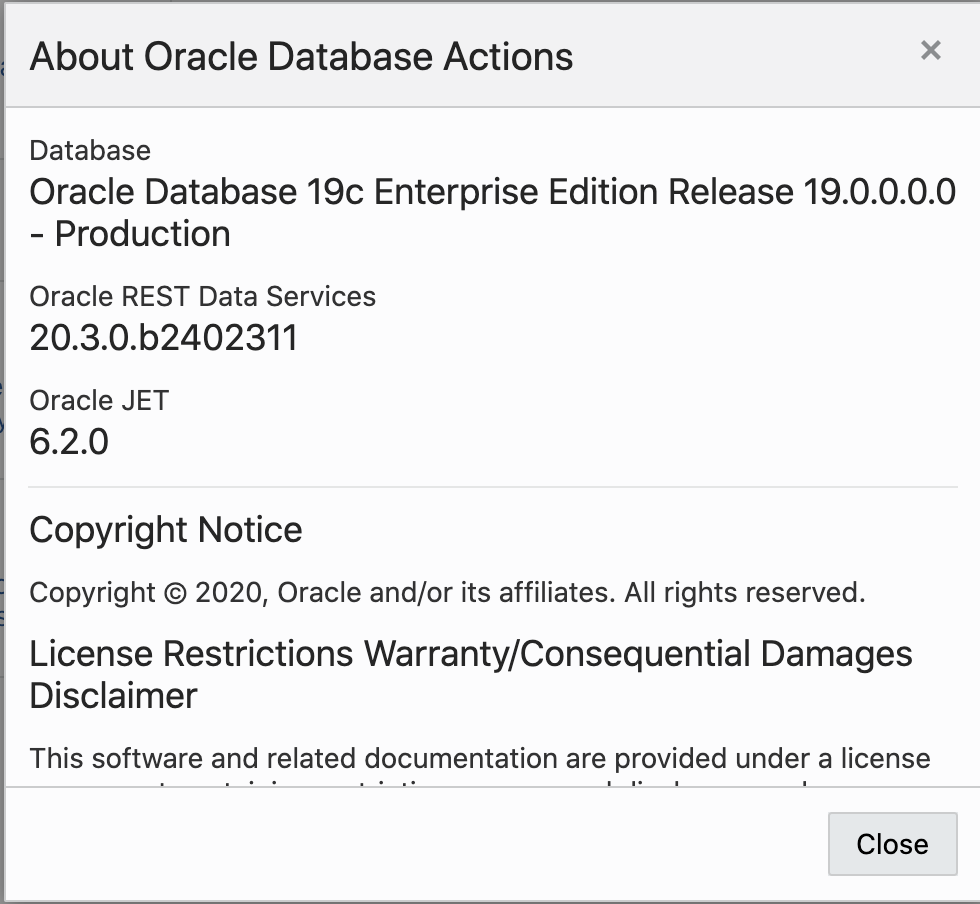
From within APEX through SQL Workshop > RESTful Services > ORDS RESTful Services…

From within APEX through Help (?) > About. In this case it’s called the APEX_LISTENER_VERSION…

ORDS repository ( ORDS_METADATA ) version
The metadata version can be obtained through an SQL query in the database…
select ords.installed_version from dual;
The above query can be executed in SQL Developer Web worksheet, APEX SQL Workshop > SQL Commands, sqlplus, sqlcl, SQL Developer. Effectively, anywhere you can run a query from.

Conclusion
It is possible for an ORDS installation to have the ords.war and ORDS_METADATA versions out of synch. This can happen if one runs a new version of ords.war against a database that already has ORDS installed without going through the installation or upgrade process or the database metadata is upgraded but the runtime ords.war is not. The latter can happen for Customer Managed ORDS on Autonomous Database. When doing so, always regularly check the application and database versions are in synch.
